class: front <!--- Para correr en ATOM - open terminal, abrir R (simplemente, R y enter) - rmarkdown::render('static/docpres/07_interacciones/7interacciones.Rmd', 'xaringan::moon_reader') About macros.js: permite escalar las imágenes como [scale 50%](path to image), hay si que grabar ese archivo js en el directorio. ---> .pull-left[ # Estadística IV ## **Kevin Carrasco & Daniela Olivares** ## **María Fernanda Nuñez** ## Sociología - UAH ## 2do Sem 2024 ## [.green[estadisticaiv.netlify.com]](https://estadisticaiv.netlify.com) ] .pull-right[ .right[ <br> ## .yellow[Sesión 6: Introducción al análisis factorial]  ] ] --- layout: true class: animated, fadeIn --- class: inverse, bottom, right, animated, slideInRight # Resumen clase anterior --- # Correlación - medida de asociación lineal entre variables - estandarizada - varía entre -1 y +1: - positiva: a medida que aumenta una, aumenta la otra - negativa: a medida que aumenta una, disminuye la otra - cero: no hay evidencia de asociación lineal entre las variables --- # Nube de puntos (scatterplot) y correlación .center[] --- class: inverse,right # **.red[Contenidos]** <br> <br> ### 1. Índices ### 2. Introducción al Análisis factorial --- class: inverse,right # **.red[Contenidos]** <br> <br> ### 1. .yellow[Índices] ### 2. Introducción al Análisis factorial --- class: middle center # ¿Por qué usar baterías de variables? --- class: middle center .center[  ] --- class: middle .pull-left-narrow[ # Preguntas y error de medición ] .pull-right-wide[ .content-box-yellow[ - Para medir hechos observables simples usualmente se utiliza **una pregunta** (ej: edad) - Fenómenos complejos se miden en general con más de una pregunta, con el objetivo de dar mejor cuenta del atributo (i.e. minimizar error de medición) ]] --- # Baterías de indicadores múltiples - en general las encuestas suelen incluir varias preguntas respecto de un mismo tema -> .red[baterías de indicadores múltiples] -- - cubren distintos aspectos de un mismo fenómeno complejo que no se agota en solo un indicador -> minimiza .red[error de medición] -- - .red[problema]: ¿cómo se analizan indicadores que están relacionados?¿cómo se muestran los resultados? --- # Análisis de indicadores en baterías .pull-left-narrow[ 1. .red[Univariado]: se sugiere presentar análisis descriptivos que contengan todos los indicadores para poder comparar frecuencias ] .pull-right-wide[ .center[  .small[(likert plot, `sjPlot`)] ] ] --- # Análisis de indicadores en baterías .pull-left-narrow[ 2\. .red[Bivariado]: tablas/gráficos de correlaciones (`corrplot`) ] .pull-right-wide[ .center[  ] ] --- # Análisis de indicadores en baterías - Se podría asumir un concepto o .red[dimensión subyacente] a la batería de items - Para facilitar el avance en el análisis (por ejemplo, relacionar ese concepto subyacente con otras variables), muchas veces se reduce la batería a algún .red[tipo de índice (sumativo/promedio)] - ¿Podemos asegurar que los items están realmente .red[midiendo lo mismo]? --- ## ¿Miden lo mismo? .center[  ] --- class: middle .pull-left-narrow[ # Preguntas y error de medición ] .pull-right-wide[ .content-box-red[ - En este marco se asume que el **indicador es distinto del atributo**, y que la medición del atributo o variable latente conlleva error - Cuando el atributo se mide con más de una pregunta, se puede intentar estimar la **variable latente** mediante índices o técnicas de **análisis factorial** ]] --- # Medición y error .pull-left[ .center[  ] ] .pull-right[ - antes de agrupar indicadores en un índice hay que evaluar si los indicadores se encuentran relacionados - -> si miden constructos similares - -> si la medición es .red[confiable] ] --- class: inverse center <br> .content-box-red[ ## .red[¿Cómo estimar el nivel de relación entre indicadores que miden un mismo constructo?] ] -- ### Distintas maneras, pero todas se basan en la técnica de la .red[correlación] --- class: bottom right ## .red[Correlaciones, baterías y dimensiones subyacentes] --- # Matriz de correlaciones (1) .center[  Matriz hipotética de indicadores que miden un mismo constructo ] --- # Ej. Matriz de correlaciones (2) .center[  Matriz hipotética de indicadores que miden constructos independientes ] --- # Ej. Matriz de correlaciones (3) .center[  Matriz hipotética de variables que miden dos constructos independientes] --- class: inverse ## .yellow[Entonces:] ### 1. analizar la .red[matriz de correlaciones] antes de generar cualquiér técnica de reducción de información (ej: crear índice) ### 2. evaluar la posibilidad de generar algún tipo de .red[índice] que resuma la información --- # Datos ejemplo - batería atribuciones de pobreza, encuesta "Desigualdad, Justicia y Participación Política" - FONDECYT Iniciación 11121203 (2013-2015) [Social justice and citizenship participation](https://jc-castillo.com/project/fondecyt-iniciacion/) .center[  ] --- ```r load("input/data/data-proc.Rdata") descr(data) library(dplyr) ``` .small[ | |var |label | n| NA.prc| mean| sd|range | |:--|:-------|:----------------------------------|----:|--------:|--------:|--------:|:-------| |2 |falthab |Razones pobreza falta de habilidad | 1228| 1.365462| 2.630293| 1.254220|4 (1-5) | |3 |malasue |Razones pobreza mala suerte | 1227| 1.445783| 2.019560| 1.140079|4 (1-5) | |1 |faltesf |Razones pobreza falta de esfuerzo | 1238| 0.562249| 3.155897| 1.290758|4 (1-5) | |4 |sisecon |Razones pobreza sistema económico | 1218| 2.168675| 4.036946| 1.095047|4 (1-5) | |5 |siseduc |Razones pobreza sistema educativo | 1227| 1.445783| 4.088835| 1.088767|4 (1-5) | ] --- ## Gráfico barras frecuencia porcentual .center[  ] --- ## Matriz de correlaciones Entonces: ```r cormat <- cor(na.omit(data)) cormat ``` ``` ## falthab malasue faltesf sisecon siseduc ## falthab 1.000000000 0.31793357 0.36246039 -0.02787884 -0.005893529 ## malasue 0.317933565 1.00000000 0.16936872 0.02755708 0.013865045 ## faltesf 0.362460395 0.16936872 1.00000000 -0.06579454 -0.020114542 ## sisecon -0.027878843 0.02755708 -0.06579454 1.00000000 0.593625639 ## siseduc -0.005893529 0.01386504 -0.02011454 0.59362564 1.000000000 ``` --- ## Matriz de correlaciones (Formato publicable) .tiny[ <table style="border-collapse:collapse; border:none;"> <tr> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;"> </th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">Razones pobreza falta de habilidad</th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">Razones pobreza mala suerte</th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">Razones pobreza falta de esfuerzo</th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">Razones pobreza sistema económico</th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">Razones pobreza sistema educativo</th> </tr> <tr> <td style="font-style:italic;">Razones pobreza falta de habilidad</td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;"> </td> </tr> <tr> <td style="font-style:italic;">Razones pobreza mala suerte</td> <td style="padding:0.2cm; text-align:center;">0.318<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;"> </td> </tr> <tr> <td style="font-style:italic;">Razones pobreza falta de esfuerzo</td> <td style="padding:0.2cm; text-align:center;">0.362<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.169<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;"> </td> </tr> <tr> <td style="font-style:italic;">Razones pobreza sistema económico</td> <td style="padding:0.2cm; text-align:center; color:#999999;">-0.028<span style="vertical-align:super;font-size:0.8em;"></span></td> <td style="padding:0.2cm; text-align:center; color:#999999;">0.028<span style="vertical-align:super;font-size:0.8em;"></span></td> <td style="padding:0.2cm; text-align:center;">-0.066<span style="vertical-align:super;font-size:0.8em;">*</span></td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;"> </td> </tr> <tr> <td style="font-style:italic;">Razones pobreza sistema educativo</td> <td style="padding:0.2cm; text-align:center; color:#999999;">-0.006<span style="vertical-align:super;font-size:0.8em;"></span></td> <td style="padding:0.2cm; text-align:center; color:#999999;">0.014<span style="vertical-align:super;font-size:0.8em;"></span></td> <td style="padding:0.2cm; text-align:center; color:#999999;">-0.020<span style="vertical-align:super;font-size:0.8em;"></span></td> <td style="padding:0.2cm; text-align:center;">0.594<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;"> </td> </tr> <tr> <td colspan="6" style="border-bottom:double black; border-top:1px solid black; font-style:italic; font-size:0.9em; text-align:right;">Computed correlation used pearson-method with listwise-deletion.</td> </tr> </table> ] --- class: inverse bottom right ## .red[Hacia la construcción de un índice] --- ## ¿Qué es un índice? -- * Es una medida estadística que permite agregar una o más variables de **distinta** naturaleza para sintetizar la parte esencial de la información contenida en un fenómeno. * Se utiliza para simplificar y resumir datos complejos en una forma más manejable y comprensible --- ## ¿Qué es un índice? * Suelen tener un punto de referencia (por ejemplo, 100) que representa una línea base o un punto de comparación -- * Pueden ser índices ponderados (distinto *peso* en cada dimensión y/o variable) o no ponderados (mismo *peso* en cada dimensión y/o variable). Depende de si las variables individuales tienen diferente importancia. * Ejemplo: Índice de precios al consumidor; Índice de desarrollo humano --- .pull-left-narrow[ ### Ejemplo índice no ponderado] .pull-right-wide[ .center[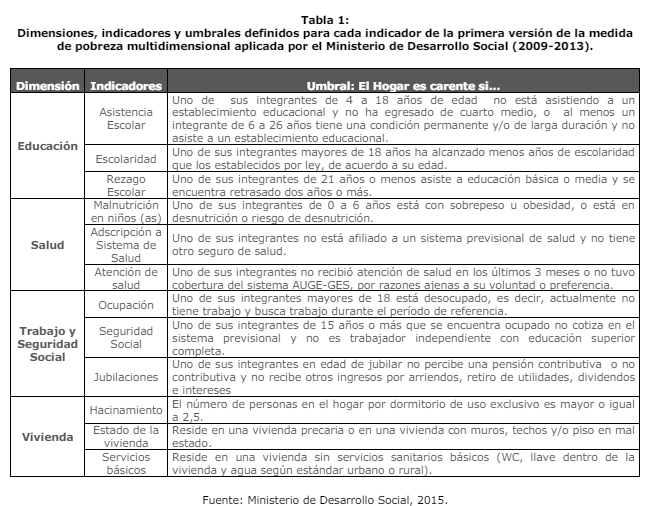] ] --- .pull-left-narrow[ ### Ejemplo índice ponderado] .center[] --- ## ¿Qué es una escala? -- * Medida de una serie de categorías ordenadas que se utilizan para medir o calificar un atributo específico. * Se construye generalmente combinando las respuestas o puntuaciones de diferentes variables en una sola medida. * Cada variable puede contribuir de forma distinta a la evaluación general de un atributo, pero el objetivo principal sigue siendo medir un atributo en específico. --- .pull-left-narrow[ ### Ejemplo de escala] .center[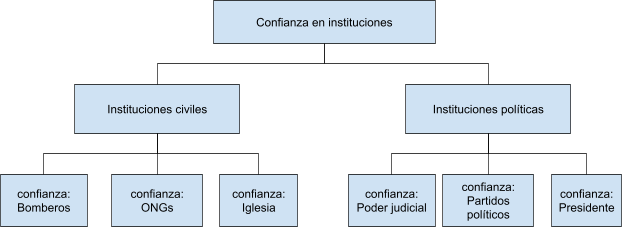] --- # Alpha de Cronbach -- - índice de consistencia interna de una batería - usualmente se reporta previo a a construcción de un índice - varía entre 0 y 1; valores más cercanos a 1 indican mayor consistencia - en general valores sobre 0.6 se consideran aceptables - más información [aquí](https://rpubs.com/jboscomendoza/alfa_cronbach_r#:~:text=El%20Alfa%20de%20Cronbach%20nos,apuntando%E2%80%9D%20en%20la%20misma%20direcci%C3%B3n.) --- # Alpha de Cronbach .pull-left[ - funcion alpha de la librería `psych` - se genera un objeto (lo llamaremos alpha). Contiene bastante información, por ahora nos enfocaremos solo en el valor de alpha (`raw_alpha`) ] .pull-right[ .small[ ```r alpha <-psych::alpha(data) ``` ``` ## Some items ( falthab malasue faltesf ) were negatively correlated with the first principal component and ## probably should be reversed. ## To do this, run the function again with the 'check.keys=TRUE' option ``` ```r alpha$total$raw_alpha ``` ``` ## [1] 0.4363206 ``` ] ] --- # Alpha de Cronbach - puntaje 0.43, por lo tanto bajo los valores aceptables de consistencia interna - esto ya se podía anticipar desde la matriz de correlaciones, que aparentemente mostraba dos dimensiones subyacentes a la batería - además, se genera un mensaje de advertencia sobre posibles items codificados a la inversa (dada la correlación entre items de dimensiones distintas) --- # Opciones - construcción de índices basados en la información de la matriz de correlaciones - análisis factorial --- class: inverse bottom right # .red[Construcción de índices] --- # Índice promedio - vamos a generar 2 índices a partir de esta batería: uno para atribución interna (falthab,faltesf,malasue) y otro para externa (sisecon,siseduc) - tema valores perdidos: - para perder el mínimo de casos se recomienda realizar índice aún con casos que no hayan respondido algún item - ya que esto distorsionaría el puntaje si fuera sumado, se hace un índice promedio, especificando que se calcule aún con valores perdidos --- # Índice de atribución interna (Promedio) ```r data <- cbind(data, "interna_prom"=rowMeans(data %>% dplyr::select(falthab,faltesf,malasue), na.rm=TRUE)) data <- cbind(data, "externa_prom"=rowMeans(data %>% dplyr::select(sisecon,siseduc), na.rm=TRUE)) ``` --- .medium[ ```r data %>% slice(11:15) ``` ``` ## falthab malasue faltesf sisecon siseduc interna_prom externa_prom ## 1 3 3 4 4 4 3.333333 4.0 ## 2 2 1 4 4 4 2.333333 4.0 ## 3 3 4 3 5 4 3.333333 4.5 ## 4 4 3 2 NA 3 3.000000 3.0 ## 5 1 1 3 3 2 1.666667 2.5 ``` ] --- # Sin embargo... .pull-left[ .small[ ```r alpha <- psych::alpha(dplyr::select(data, falthab, faltesf, malasue)) alpha$total$raw_alpha ``` ``` ## [1] 0.5384986 ``` ] ] .pull-right[ .small[ ```r alpha <- psych::alpha(dplyr::select(data, sisecon, siseduc)) alpha$total$raw_alpha ``` ``` ## [1] 0.7434989 ``` ] ] --- class: inverse ## Resumen índices - baterías y dimensiones subyacentes (latentes) - evaluación de consistencia interna (previo a construcción de índices) - índices y .red[factores] --- class: inverse,right # **.red[Contenidos]** <br> <br> ### 1. Índices ### 2. .yellow[Introducción al Análisis factorial] --- class: middle .pull-left-narrow[ # Variables latentes (1) ] .pull-right-wide[ .content-box-red[ - La mayor parte de las variables en el mundo social no son directamente observables. Esto las hace constructos hipotéticos **latentes** - La medición de variables latentes se realiza a partir de indicadores observables, tales como los .red[ítems de una batería/ cuestionario] ] ] --- class: middle .pull-left-narrow[ # Variables latentes (2) ] .pull-right-wide[ .content-box-yellow[ - Lo latente puede ser entendido como la .red[varianza compartida] por diferentes indicadores observados - La medición de variables latentes se encuentra asociada al .red[modelo de factor común] (Thurstone) y al análisis factorial ] ] --- class: middle .pull-left-narrow[ # Análisis factorial Es un método que permite: ] .pull-right-wide[ .content-box-gray[ - identificar la varianza común a una serie de indicadores - establecer la contribución de cada indicador a la varianza común - estimar posteriormente un índice (puntaje factorial) para cada factor, con mayor precisión que un promedio bruto ]] --- # Análisis factorial - Un factor es una variable no observada o **latente** que da cuenta de las correlaciones entre indicadores - los indicadores están correlacionados porque comparten una causa común - concepto de **independencia condicional** - El o los factores darían cuenta (i.e. causarían) de la **covariación** entre una serie de medidas observadas (indicadores) --- class: middle .pull-left-narrow[ .content-box-red[ <br> # Objetivos del análisis factorial <br> <br> <br> <br> <br><br> ]] .pull-right-wide[ <br> - .red[Teórico]: relacionar datos con dimensiones latentes basadas en conceptos (validez de constructo) - .blue[Pragmático]: hacer sentido de un conjunto de datos, reducción de dimensiones y obtención de puntajes - .green[Metodológico]: aislar el error (varianza única) de la varianza común ] --- # Alternativas en análisis factorial - .red[exploratorio (EFA)]: Permite explorar las dimensiones que subyacen a una escala - .red[confirmatorio (CFA)]: Permite confirmar las dimensiones que subyacen a una escala, aislando el error de medición en la estimación --- # Análisis factorial exploratorio (EFA) - Forma de análisis factorial donde se estiman la o las variables latentes a un conjunto de indicadores, **sin una especificación previa** de la estructura factorial. -- - Preguntas a responder: - ¿Cuántos factores subyacen a un conjunto de indicadores? - ¿Cómo se relacionan los indicadores con los factores? - ¿Cómo es la calidad del modelo estimado? --- .content-box-green[ # Características EFA ] .pull-left-narrow[ .center[ <br> 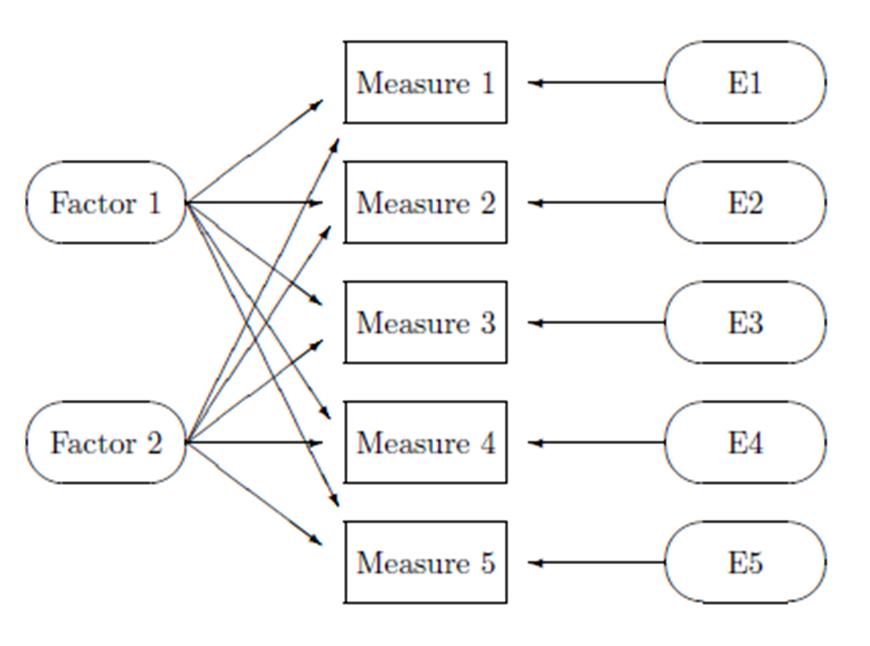 ]] .pull-right-wide[ - Basado en la matriz de correlaciones - Modelo estandarizado (varianza factores=1) - Diferentes métodos de extracción de factores - Determinación del número y "calidad" de las dimensiones (continuas) subyacentes a una escala ] --- # Ejemplo .small[ ``` ## Parallel analysis suggests that the number of factors = 2 and the number of components = NA ``` <table style="border-collapse:collapse; border:none;"> <caption style="font-weight: bold; text-align:left;">Análisis factorial atribuciones de pobreza</caption> <tr> <th style="border-top:double black; padding:0.2cm;"> </th> <th style="border-top:double black; padding:0.2cm;">Factor 1</th> <th style="border-top:double black; padding:0.2cm;">Factor 2</th> <th style="border-top:double black; padding:0.2cm; font-style:italic; color:#666666;">Communality</th> </tr> <tr> <td style=" border-top:1px solid black;">Razones pobreza falta de habilidad</td> <td style="padding:0.2cm; text-align:center; color:#cccccc; border-top:1px solid black;">-0.01</td> <td style="padding:0.2cm; text-align:center; border-top:1px solid black;">0.83</td> <td style="padding:0.2cm; font-style:italic; color:#666666; text-align:center; border-top:1px solid black;">0.69</td> </tr> <tr> <td style="">Razones pobreza falta de esfuerzo</td> <td style="padding:0.2cm; text-align:center; color:#cccccc;">-0.06</td> <td style="padding:0.2cm; text-align:center;">0.43</td> <td style="padding:0.2cm; font-style:italic; color:#666666; text-align:center;">0.19</td> </tr> <tr> <td style="">Razones pobreza mala suerte</td> <td style="padding:0.2cm; text-align:center; color:#cccccc;">0.03</td> <td style="padding:0.2cm; text-align:center;">0.38</td> <td style="padding:0.2cm; font-style:italic; color:#666666; text-align:center;">0.15</td> </tr> <tr> <td style="">Razones pobreza sistema económico</td> <td style="padding:0.2cm; text-align:center;">1.00</td> <td style="padding:0.2cm; text-align:center; color:#cccccc;">-0.02</td> <td style="padding:0.2cm; font-style:italic; color:#666666; text-align:center;">0.99</td> </tr> <tr> <td style="">Razones pobreza sistema educativo</td> <td style="padding:0.2cm; text-align:center;">0.60</td> <td style="padding:0.2cm; text-align:center; color:#cccccc;">0.01</td> <td style="padding:0.2cm; font-style:italic; color:#666666; text-align:center;">0.36</td> </tr> <tr> <td style="padding:0.2cm; font-style:italic;">Total Communalities</td> <td style="padding:0.2cm; text-align:center; font-style:italic;" colspan="2"></td> <td style="padding:0.2cm; text-align:center; font-style:italic;">2.37</td> </tr> <tr> <td style="padding:0.2cm; font-style:italic; border-bottom:double;">Cronbach's α</td> <td style="padding:0.2cm; text-align:center; font-style:italic; border-bottom:double;">0.75</td> <td style="padding:0.2cm; text-align:center; font-style:italic; border-bottom:double;">0.54</td> <td style="padding:0.2cm; text-align:center; font-style:italic; border-bottom:double;"></td> </tr> </table> ] --- .pull-left-narrow[ .content-box-purple[ <br> # Conceptos y parámetros <br> <br> <br> <br> <br> ] ] .pull-right-wide[ - **Factores**: variables latentes que están a la base de las correlaciones entre los indicadores - **Cargas factoriales**: medida estandarizada de asociación (correlación) entre el indicador y la variable latente - **Comunalidad**: proporción del indicador que se asocia a factor(es) comun(es) ] --- class: middle .pull-left-narrow[ .content-box-yellow[ <br> # Conceptos y parámetros (2) <br> <br> <br> ] ] .pull-right-wide[ - **Varianza única** (uniqueness): 1-comunalidad - **Eigenvalues**: medida de proporción de la varianza total correspondiente a cada uno de los factor (SS loadings) - **Proporción de varianza** explicada por el factor = eigenvalue / número de indicadores ] --- class: roja # Resumen - dimensiones subyacentes = factores - análisis factorial - relación entre indicadores y dimensiones - estimación de número de dimensiones probables subyacentes a batería --- class: inverse middle ## .red[Práctica análisis factorial] [.yellow[https://estadisticaiv.netlify.app/practicos/05-content]](https://estadisticaiv.netlify.app/practicos/05-content) --- class: front .pull-left[ # Estadística IV ## **Kevin Carrasco & Daniela Olivares** ## **María Fernanda Nuñez** ## Sociología - UAH ## 2do Sem 2024 ## [.green[estadisticaiv.netlify.com]](https://estadisticaiv.netlify.com) ] .pull-right[ .right[ <br> ## .yellow[Sesión 6: Introducción al análisis factorial]  ] ]