class: front <!--- Para correr en ATOM - open terminal, abrir R (simplemente, R y enter) - rmarkdown::render('static/docpres/07_interacciones/7interacciones.Rmd', 'xaringan::moon_reader') About macros.js: permite escalar las imágenes como [scale 50%](path to image), hay si que grabar ese archivo js en el directorio. ---> .pull-left[ # Estadística IV ## **Kevin Carrasco & Daniela Olivares** ## **María Fernanda Nuñez** ## Sociología - UAH ## 2do Sem 2024 ## [.green[estadisticaiv.netlify.com]](https://estadisticaiv.netlify.com) ] .pull-right[ .right[ <br> ## .yellow[Sesión 8: AFE y puntajes factoriales]  ] ] --- layout: true class: animated, fadeIn --- class: inverse, bottom, right, animated, slideInRight # Resumen hasta ahora --- class: middle center # ¿Por qué usar baterías de variables? --- class: middle center .center[ 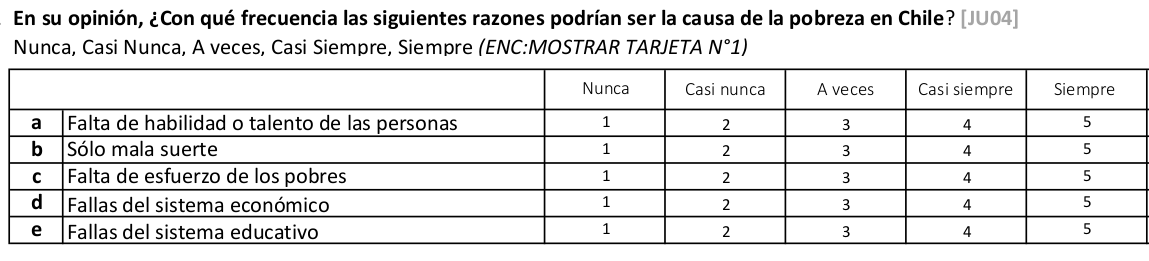 ] --- class: middle .pull-left-narrow[ # Preguntas y error de medición ] .pull-right-wide[ .content-box-yellow[ - Para medir hechos observables simples usualmente se utiliza **una pregunta** (ej: edad) - Fenómenos complejos se miden en general con más de una pregunta, con el objetivo de dar mejor cuenta del atributo (i.e. minimizar error de medición) ]] --- # Análisis de indicadores en baterías .pull-left-narrow[ 1. .red[Univariado]: se sugiere presentar análisis descriptivos que contengan todos los indicadores para poder comparar frecuencias ] .pull-right-wide[ .center[ <!-- --> .small[(likert plot, `sjPlot`)] ] ] --- # Análisis de indicadores en baterías .tiny[ <table style="border-collapse:collapse; border:none;"> <tr> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;"> </th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">Grado de acuerdo: Mujeres son mas<br>refinadas</th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">Grado de acuerdo: Mujeres deberian ser<br>protegidas</th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">Grado de acuerdo: Mujeres consiguen<br>privilegios en nombre de igualdad</th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">Grado de acuerdo: Mujeres derrotadas se<br>quejan de discriminacion</th> </tr> <tr> <td style="font-style:italic;">Grado de acuerdo: Mujeres son mas<br>refinadas</td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;"> </td> </tr> <tr> <td style="font-style:italic;">Grado de acuerdo: Mujeres deberian ser<br>protegidas</td> <td style="padding:0.2cm; text-align:center;">0.364<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;"> </td> </tr> <tr> <td style="font-style:italic;">Grado de acuerdo: Mujeres consiguen<br>privilegios en nombre de igualdad</td> <td style="padding:0.2cm; text-align:center;">0.224<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.199<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;"> </td> </tr> <tr> <td style="font-style:italic;">Grado de acuerdo: Mujeres derrotadas se<br>quejan de discriminacion</td> <td style="padding:0.2cm; text-align:center;">0.183<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.163<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.453<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;"> </td> </tr> <tr> <td colspan="5" style="border-bottom:double black; border-top:1px solid black; font-style:italic; font-size:0.9em; text-align:right;">Computed correlation used pearson-method with listwise-deletion.</td> </tr> </table> ] --- # Análisis de indicadores en baterías - Se podría asumir un concepto o .red[dimensión subyacente] a la batería de items - Para facilitar el avance en el análisis (por ejemplo, relacionar ese concepto subyacente con otras variables), muchas veces se reduce la batería a algún .red[tipo de índice (sumativo/promedio)] - ¿Podemos asegurar que los items están realmente .red[midiendo lo mismo]? --- class: bottom right ## .red[Correlaciones, baterías y dimensiones subyacentes] --- class: inverse ## .yellow[Entonces:] ### 1. analizar la .red[matriz de correlaciones] antes de generar cualquiér técnica de reducción de información (ej: crear índice) ### 2. evaluar la posibilidad de generar algún tipo de .red[índice] que resuma la información --- ## Matriz de correlaciones Entonces: .tiny[ <table style="border-collapse:collapse; border:none;"> <tr> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;"> </th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">Grado de acuerdo: Mujeres son mas<br>refinadas</th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">Grado de acuerdo: Mujeres deberian ser<br>protegidas</th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">Grado de acuerdo: Mujeres consiguen<br>privilegios en nombre de igualdad</th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">Grado de acuerdo: Mujeres derrotadas se<br>quejan de discriminacion</th> </tr> <tr> <td style="font-style:italic;">Grado de acuerdo: Mujeres son mas<br>refinadas</td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;"> </td> </tr> <tr> <td style="font-style:italic;">Grado de acuerdo: Mujeres deberian ser<br>protegidas</td> <td style="padding:0.2cm; text-align:center;">0.364<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;"> </td> </tr> <tr> <td style="font-style:italic;">Grado de acuerdo: Mujeres consiguen<br>privilegios en nombre de igualdad</td> <td style="padding:0.2cm; text-align:center;">0.224<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.199<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;"> </td> </tr> <tr> <td style="font-style:italic;">Grado de acuerdo: Mujeres derrotadas se<br>quejan de discriminacion</td> <td style="padding:0.2cm; text-align:center;">0.183<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.163<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.453<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;"> </td> </tr> <tr> <td colspan="5" style="border-bottom:double black; border-top:1px solid black; font-style:italic; font-size:0.9em; text-align:right;">Computed correlation used pearson-method with listwise-deletion.</td> </tr> </table> ] --- # Alpha de Cronbach -- - índice de consistencia interna de una batería - usualmente se reporta previo a a construcción de un índice - varía entre 0 y 1; valores más cercanos a 1 indican mayor consistencia - en general valores sobre 0.6 se consideran aceptables - más información [aquí](https://rpubs.com/jboscomendoza/alfa_cronbach_r#:~:text=El%20Alfa%20de%20Cronbach%20nos,apuntando%E2%80%9D%20en%20la%20misma%20direcci%C3%B3n.) --- # Alpha de Cronbach .pull-left[ - funcion alpha de la librería `psych` - se genera un objeto (lo llamaremos alpha). Contiene bastante información, por ahora nos enfocaremos solo en el valor de alpha (`raw_alpha`) ] .pull-right[ .small[ ```r alpha <-psych::alpha(data) alpha$total$raw_alpha ``` ``` ## [1] 0.5859888 ``` ] ] --- # Alpha de Cronbach - puntaje 0.58, por lo tanto bajo los valores aceptables de consistencia interna --- # Opciones - construcción de índices basados en la información de la matriz de correlaciones - análisis factorial --- class: inverse bottom right # .red[Construcción de índices] --- # Índice promedio - vamos a generar 2 índices a partir de esta batería: uno para sexismo benevolente y otro para sexismo hostil. --- # Índice de sexismo (Promedio) ```r data <- cbind(data, "benevolente_prom"=rowMeans(data %>% dplyr::select(son_refinadas,ser_protegidas), na.rm=TRUE)) data <- cbind(data, "hostil_prom"=rowMeans(data %>% dplyr::select(consiguen_privilegios,quejan_discriminacion), na.rm=TRUE)) ``` --- # Sin embargo... .pull-left[ .small[ ```r alpha <- psych::alpha(dplyr::select(data, son_refinadas, ser_protegidas)) alpha$total$raw_alpha ``` ``` ## [1] 0.5204052 ``` ] ] .pull-right[ .small[ ```r alpha <- psych::alpha(dplyr::select(data, consiguen_privilegios, quejan_discriminacion)) alpha$total$raw_alpha ``` ``` ## [1] 0.6206947 ``` ] ] --- class: inverse ## Resumen índices - baterías y dimensiones subyacentes (latentes) - evaluación de consistencia interna (previo a construcción de índices) - índices y .red[factores] --- class: inverse,right # **.red[Contenidos]** <br> <br> ### 1. .yellow[Análisis factorial exploratorio] --- class: middle .pull-left-narrow[ # Variables latentes (1) ] .pull-right-wide[ .content-box-red[ - La mayor parte de las variables en el mundo social no son directamente observables. Esto las hace constructos hipotéticos **latentes** - La medición de variables latentes se realiza a partir de indicadores observables, tales como los .red[ítems de una batería/ cuestionario] ] ] --- class: middle .pull-left-narrow[ # Variables latentes (2) ] .pull-right-wide[ .content-box-yellow[ - Lo latente puede ser entendido como la .red[varianza compartida] por diferentes indicadores observados - La medición de variables latentes se encuentra asociada al .red[modelo de factor común] (Thurstone) y al análisis factorial ] ] --- --- # Factor común .pull-left[ - Cada indicador en un set de medidas observadas es una .red[función lineal] de uno o más factores comunes y un factor único - Como referencia podemos usar la .red[teoría clásica de test] (CTT), que divide el puntaje de los indicadores entre puntaje verdadero y error ] -- .pull-right[ <br> `$$X=T+E$$` Donde - X= puntaje observado, - T= puntaje verdadero, y - E= error ] --- # Modelo de factor común .pull-left[ - La existencia de un solo ítem por constructo no permite aislar puntaje verdadero del error - Si existen más ítems, podemos estimar un **análisis factorial** y distinguir entre **varianza común** (compartida con otros indicadores) y **varianza única** (o error) ] .pull-right[ .center[ 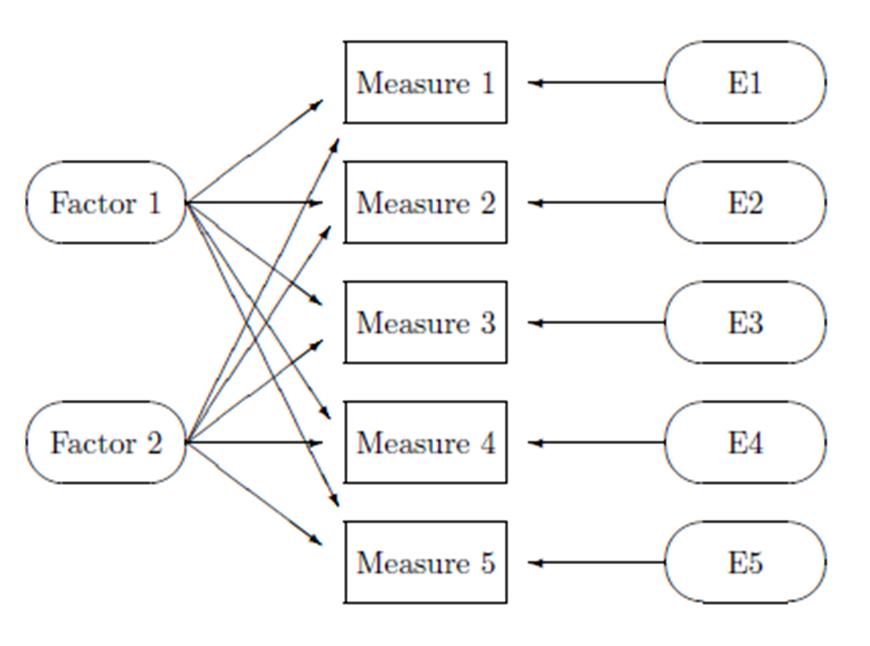 ] ] --- class: middle .pull-left-narrow[ # Análisis factorial Es un método que permite: ] .pull-right-wide[ .content-box-gray[ - identificar la varianza común a una serie de indicadores - establecer la contribución de cada indicador a la varianza común - estimar posteriormente un índice (puntaje factorial) para cada factor, con mayor precisión que un promedio bruto ]] --- # Análisis factorial - Un factor es una variable no observada o **latente** que da cuenta de las correlaciones entre indicadores - los indicadores están correlacionados porque comparten una causa común - concepto de **independencia condicional** - El o los factores darían cuenta (i.e. causarían) de la **covariación** entre una serie de medidas observadas (indicadores) --- class: middle .pull-left-narrow[ .content-box-red[ <br> # Objetivos del análisis factorial <br> <br> <br> <br> <br><br> ]] .pull-right-wide[ <br> - .red[Teórico]: relacionar datos con dimensiones latentes basadas en conceptos (validez de constructo) - .blue[Pragmático]: hacer sentido de un conjunto de datos, reducción de dimensiones y obtención de puntajes - .green[Metodológico]: aislar el error (varianza única) de la varianza común ] --- # Alternativas en análisis factorial - .red[exploratorio (EFA)]: Permite explorar las dimensiones que subyacen a una escala - .red[confirmatorio (CFA)]: Permite confirmar las dimensiones que subyacen a una escala, aislando el error de medición en la estimación --- # Análisis factorial exploratorio (EFA) - Forma de análisis factorial donde se estiman la o las variables latentes a un conjunto de indicadores, **sin una especificación previa** de la estructura factorial. -- - Preguntas a responder: - ¿Cuántos factores subyacen a un conjunto de indicadores? - ¿Cómo se relacionan los indicadores con los factores? - ¿Cómo es la calidad del modelo estimado? --- .content-box-green[ # Características EFA ] .pull-left-narrow[ .center[ <br>  ]] .pull-right-wide[ - Basado en la matriz de correlaciones - Modelo estandarizado (varianza factores=1) - Diferentes métodos de extracción de factores - Determinación del número y "calidad" de las dimensiones (continuas) subyacentes a una escala ] --- # Ejemplo .small[ ``` ## Parallel analysis suggests that the number of factors = 2 and the number of components = NA ``` <table style="border-collapse:collapse; border:none;"> <caption style="font-weight: bold; text-align:left;">Análisis factorial atribuciones de pobreza</caption> <tr> <th style="border-top:double black; padding:0.2cm;"> </th> <th style="border-top:double black; padding:0.2cm;">Factor 1</th> <th style="border-top:double black; padding:0.2cm;">Factor 2</th> <th style="border-top:double black; padding:0.2cm; font-style:italic; color:#666666;">Communality</th> </tr> <tr> <td style=" border-top:1px solid black;">Grado de acuerdo: Mujeres son mas<br>refinadas</td> <td style="padding:0.2cm; text-align:center; color:#cccccc; border-top:1px solid black;">0.14</td> <td style="padding:0.2cm; text-align:center; border-top:1px solid black;">0.60</td> <td style="padding:0.2cm; font-style:italic; color:#666666; text-align:center; border-top:1px solid black;">0.38</td> </tr> <tr> <td style="">Grado de acuerdo: Mujeres deberian ser<br>protegidas</td> <td style="padding:0.2cm; text-align:center; color:#cccccc;">0.12</td> <td style="padding:0.2cm; text-align:center;">0.57</td> <td style="padding:0.2cm; font-style:italic; color:#666666; text-align:center;">0.34</td> </tr> <tr> <td style="">Grado de acuerdo: Mujeres consiguen<br>privilegios en nombre de igualdad</td> <td style="padding:0.2cm; text-align:center;">0.65</td> <td style="padding:0.2cm; text-align:center; color:#cccccc;">0.21</td> <td style="padding:0.2cm; font-style:italic; color:#666666; text-align:center;">0.47</td> </tr> <tr> <td style="">Grado de acuerdo: Mujeres derrotadas se<br>quejan de discriminacion</td> <td style="padding:0.2cm; text-align:center;">0.65</td> <td style="padding:0.2cm; text-align:center; color:#cccccc;">0.15</td> <td style="padding:0.2cm; font-style:italic; color:#666666; text-align:center;">0.44</td> </tr> <tr> <td style="padding:0.2cm; font-style:italic;">Total Communalities</td> <td style="padding:0.2cm; text-align:center; font-style:italic;" colspan="2"></td> <td style="padding:0.2cm; text-align:center; font-style:italic;">1.63</td> </tr> <tr> <td style="padding:0.2cm; font-style:italic; border-bottom:double;">Cronbach's α</td> <td style="padding:0.2cm; text-align:center; font-style:italic; border-bottom:double;">0.62</td> <td style="padding:0.2cm; text-align:center; font-style:italic; border-bottom:double;">0.52</td> <td style="padding:0.2cm; text-align:center; font-style:italic; border-bottom:double;"></td> </tr> </table> ] --- .pull-left-narrow[ .content-box-purple[ <br> # Conceptos y parámetros <br> <br> <br> <br> <br> ] ] .pull-right-wide[ - **Factores**: variables latentes que están a la base de las correlaciones entre los indicadores - **Cargas factoriales**: medida estandarizada de asociación (correlación) entre el indicador y la variable latente - **Comunalidad**: proporción del indicador que se asocia a factor(es) comun(es) ] --- class: middle .pull-left-narrow[ .content-box-yellow[ <br> # Conceptos y parámetros (2) <br> <br> <br> ] ] .pull-right-wide[ - **Varianza única** (uniqueness): 1-comunalidad - **Eigenvalues**: medida de proporción de la varianza total correspondiente a cada uno de los factor (SS loadings) - **Proporción de varianza** explicada por el factor = eigenvalue / número de indicadores ] --- class: middle .pull-left-narrow[ .content-box-blue[ <br> # Pasos en el análisis <br> <br> <br> ]] .pull-right-wide[ - Estimación de matriz de correlaciones - Extraccion de factores - Decisión sobre número de factores - Rotación - Interpretación y reporte - Obtención de puntajes factoriales ] --- class: middle .pull-left-narrow[ .content-box-blue[ <br> # Pasos en el análisis <br> <br> <br> ]] .pull-right-wide[ - Estimación de matriz de correlaciones - Extraccion de factores - Decisión sobre número de factores - Rotación - Interpretación y reporte - .red[Obtención de puntajes factoriales] ] --- # Supuestos a evaluar - Nivel de medición de variables, normalidad (eventualmente test de normalidad multivariado, ej: Shapiro Wilk multivariado) - Test de adecuación muestal (KMO) .medium[ - varía entre 0 y 1, contrasta si las correlaciones parciales entre las variables son pequeñas. - valores pequeños (menores a 0.5) indican que los datos no serían adecuados para EFA, ya que las correlaciones entre pares de variables no pueden ser explicadas por otras variables ] --- # Supuestos a evaluar (2) - Nivel de correlaciones de la matriz: test de esfericidad de Bartlett - se utiliza para evaluar la hipótesis que la matriz de correlaciones es una matriz identidad (en la diagonal=1 y bajo la diagonal=0) - se busca significación (p `\(<\)` 0.05), ya que se espera que las variables estén correlacionadas --- # Supuestos a evaluar (2) .tiny[ <table style="border-collapse:collapse; border:none;"> <tr> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;"> </th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">Grado de acuerdo: Mujeres son mas<br>refinadas</th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">Grado de acuerdo: Mujeres deberian ser<br>protegidas</th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">Grado de acuerdo: Mujeres consiguen<br>privilegios en nombre de igualdad</th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">Grado de acuerdo: Mujeres derrotadas se<br>quejan de discriminacion</th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">benevolente_prom</th> <th style="font-style:italic; font-weight:normal; border-top:double black; border-bottom:1px solid black; padding:0.2cm;">hostil_prom</th> </tr> <tr> <td style="font-style:italic;">Grado de acuerdo: Mujeres son mas<br>refinadas</td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;">0.364<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.224<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.183<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.863<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.238<span style="vertical-align:super;font-size:0.8em;">***</span></td> </tr> <tr> <td style="font-style:italic;">Grado de acuerdo: Mujeres deberian ser<br>protegidas</td> <td style="padding:0.2cm; text-align:center;">0.364<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;">0.199<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.163<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.784<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.212<span style="vertical-align:super;font-size:0.8em;">***</span></td> </tr> <tr> <td style="font-style:italic;">Grado de acuerdo: Mujeres consiguen<br>privilegios en nombre de igualdad</td> <td style="padding:0.2cm; text-align:center;">0.224<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.199<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;">0.453<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.257<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.842<span style="vertical-align:super;font-size:0.8em;">***</span></td> </tr> <tr> <td style="font-style:italic;">Grado de acuerdo: Mujeres derrotadas se<br>quejan de discriminacion</td> <td style="padding:0.2cm; text-align:center;">0.183<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.163<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.453<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;">0.210<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.863<span style="vertical-align:super;font-size:0.8em;">***</span></td> </tr> <tr> <td style="font-style:italic;">benevolente_prom</td> <td style="padding:0.2cm; text-align:center;">0.863<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.784<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.257<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.210<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;"> </td> <td style="padding:0.2cm; text-align:center;">0.273<span style="vertical-align:super;font-size:0.8em;">***</span></td> </tr> <tr> <td style="font-style:italic;">hostil_prom</td> <td style="padding:0.2cm; text-align:center;">0.238<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.212<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.842<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.863<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;">0.273<span style="vertical-align:super;font-size:0.8em;">***</span></td> <td style="padding:0.2cm; text-align:center;"> </td> </tr> <tr> <td colspan="7" style="border-bottom:double black; border-top:1px solid black; font-style:italic; font-size:0.9em; text-align:right;">Computed correlation used pearson-method with listwise-deletion.</td> </tr> </table> ] --- # Métodos de extracción En el análisis factorial exploratorio (AFE), los **métodos de extracción** se refieren a las técnicas que se utilizan para determinar los factores/ variables latentes a las variables observadas. Los tres métodos principales son: - **Factores principales** - **Factores principales iterados** - **Maximum likelihood** --- # Métodos de extracción - **Factores principales** Este es uno de los métodos más comunes para la extracción de factores. Se basa en la descomposición de la matriz de correlaciones para identificar los factores que explican la mayor cantidad de varianza compartida por las variables. Es útil cuando el objetivo es reducir la dimensionalidad manteniendo el máximo de información posible. --- # Métodos de extracción - **Factores principales iterados**: Este método es una variante del anterior. Estima las **comunalidades** (la cantidad de varianza de cada variable explicada por los factores) iterativamente. Reemplaza los valores iniciales de las comunalidades en la matriz de correlaciones con las comunalidades estimadas a partir de los **factor loadings** (cargas factoriales) y repite el proceso hasta que se alcance una solución estable. Este método mejora la precisión de la estimación de los factores. --- # Métodos de extracción - **Maximum likelihood**: Este método busca encontrar los parámetros del modelo que maximicen la probabilidad de que los datos observados sean replicados por el modelo factorial. Es útil cuando se quiere hacer inferencia estadística sobre los factores, ya que permite realizar pruebas de hipótesis y obtener intervalos de confianza para los factores y sus cargas. Es más robusto, pero requiere que los datos cumplan ciertos supuestos como normalidad multivariada. --- # Instrumentos y criterios de selección del número de factores - Criterio de Kaiser: eigenvalues (cantidad de varianza explicada por cada factor) mayores a 1 - Scree plot (gráfico de sedimentación) - **Análisis paralelo**: comparación de eigenvalues de la muestra con eigenvalues de datos aleatorios. Nº apropiado de factores: numero de eigenvalues de los datos reales que son mayores que sus correspondientes eigenvalues de datos aleatorios --- # Screeplot y análisis paralelo .center[ 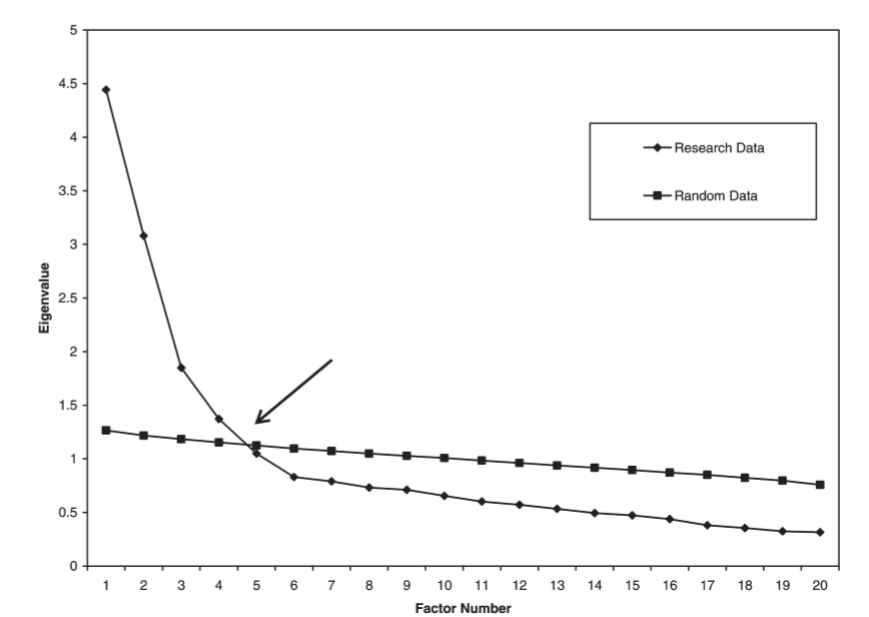 ] --- .pull-left-narrow[ # Tipos de rotación - **Ortogonal**: asume que los factores no se encuentran correlacionados - **Oblicua**: permite correlación entre factores ] .pull-right-wide[ .center[ 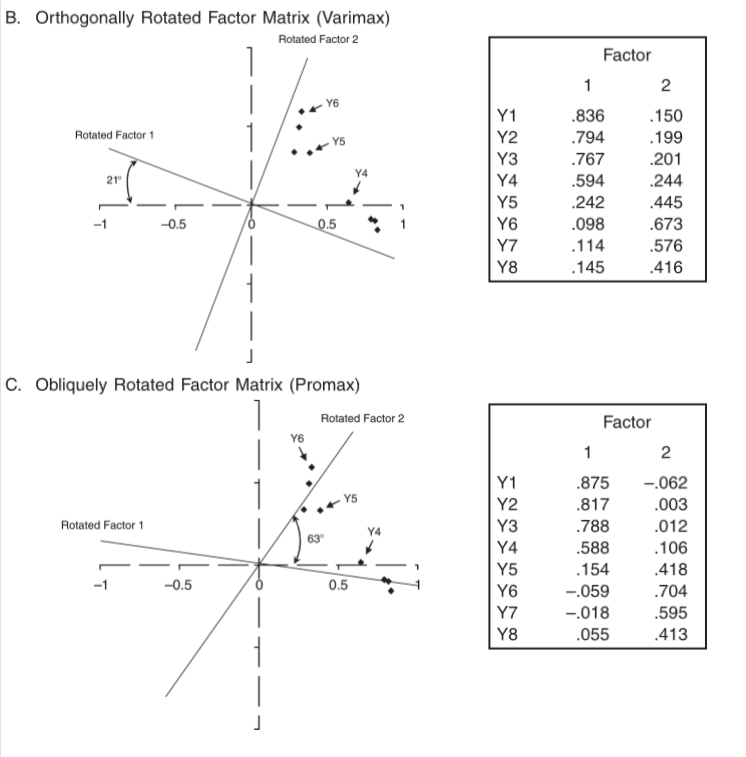 ] ] --- # Puntajes factoriales Los puntajes factoriales son “estimaciones” (predicciones) de puntajes en los factores para cada observación en los datos. * Estos puntajes pueden utilizarse en análisis posteriores * Se pueden calcular puntajes para cada observación en cada factor utilizando un método de regresión * Estas nuevas variables se estandarizan con media 0 y desviación estándar 1 --- ``` ## Factor Analysis using method = ml ## Call: fa(r = fa, nfactors = 2, scores = "regression", fm = "ml") ## Standardized loadings (pattern matrix) based upon correlation matrix ## ML1 ML2 h2 u2 com ## son_refinadas 0.01 0.62 0.38 0.62 1 ## ser_protegidas -0.01 0.58 0.34 0.66 1 ## consiguen_privilegios 0.67 0.03 0.47 0.53 1 ## quejan_discriminacion 0.68 -0.03 0.44 0.56 1 ## ## ML1 ML2 ## SS loadings 0.90 0.72 ## Proportion Var 0.23 0.18 ## Cumulative Var 0.23 0.41 ## Proportion Explained 0.56 0.44 ## Cumulative Proportion 0.56 1.00 ## ## With factor correlations of ## ML1 ML2 ## ML1 1.00 0.47 ## ML2 0.47 1.00 ## ## Mean item complexity = 1 ## Test of the hypothesis that 2 factors are sufficient. ## ## df null model = 6 with the objective function = 0.45 with Chi Square = 1522.89 ## df of the model are -1 and the objective function was 0 ## ## The root mean square of the residuals (RMSR) is 0 ## The df corrected root mean square of the residuals is NA ## ## The harmonic n.obs is 3354 with the empirical chi square 0 with prob < NA ## The total n.obs was 3417 with Likelihood Chi Square = 0 with prob < NA ## ## Tucker Lewis Index of factoring reliability = 1.004 ## Fit based upon off diagonal values = 1 ## Measures of factor score adequacy ## ML1 ML2 ## Correlation of (regression) scores with factors 0.80 0.75 ## Multiple R square of scores with factors 0.64 0.56 ## Minimum correlation of possible factor scores 0.28 0.13 ``` --- ``` ## benevolente_prom hostil_prom ML1 ML2 ## 1 4.5 4.0 0.62586434 0.65986183 ## 2 4.5 3.5 0.25445615 0.67328242 ## 3 4.5 4.0 0.62498033 0.69225511 ## 4 3.5 3.5 -0.05380749 -0.36360884 ## 5 4.0 4.0 0.53314791 0.22298473 ## 6 4.0 4.0 0.53314791 0.22298473 ## 7 4.0 3.0 -0.33161523 0.05429558 ## 8 4.0 3.0 -0.33161523 0.05429558 ## 9 4.0 4.0 0.53314791 0.22298473 ## 10 4.0 3.0 -0.39347262 -0.01107631 ``` --- ## Factor 1 ``` ## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's ## -2.80036 -0.45533 0.19260 0.00396 0.53315 1.64432 120 ``` ## Factor 2 ``` ## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's ## -3.19764 -0.36361 0.13979 0.00049 0.45705 1.36319 120 ``` --- class: roja # Resumen - dimensiones subyacentes = factores - análisis factorial - relación entre indicadores y dimensiones - estimación de número de dimensiones probables subyacentes a batería - rotación - obtención de puntajes factoriales (índices ponderados) --- class: inverse middle ## .red[Práctica análisis factorial exploratorio] [.yellow[https://estadisticaiv.netlify.app/practicos/07-content]](https://estadisticaiv.netlify.app/practicos/07-content) --- class: front .pull-left[ # Estadística IV ## **Kevin Carrasco & Daniela Olivares** ## **María Fernanda Nuñez** ## Sociología - UAH ## 2do Sem 2024 ## [.green[estadisticaiv.netlify.com]](https://estadisticaiv.netlify.com) ] .pull-right[ .right[ <br> ## .yellow[Sesión 7: Análisis factorial exploratorio]  ] ]