La siguiente práctica tiene el objetivo de introducir la idea central del análisis de correspondencia. Para ello, utilizaremos la base de datos de la cuarta ola del Estudio Longitudinal Social de Chile (2019) con el objetivo de analizar agrupaciones de variables categóricas nominales.
Preparación datos
Comencemos por preparar nuestros datos. Iniciamos cargando las librerías necesarias.
Código
pacman::p_load(tidyverse, # Manipulacion datos sjPlot, # Tablas psych, # Correlaciones DescTools, # Tablas ggplot2, # graficos en general broom, rempsyc, FactoMineR, # analisis de correspondencia factoextra # analisis de correspondencia )options(scipen =999) # para desactivar notacion cientificarm(list =ls()) # para limpiar el entorno de trabajo
Cargamos los datos directamente desde internet.
Código
#cargamos la base de datos desde internetload(url("https://dataverse.harvard.edu/api/access/datafile/7245118")) dim(elsoc_long_2016_2022.2)
[1] 18035 750
Contamos con 750 variables (columnas) y 18035 observaciones (filas).
Código
proc_data <- elsoc_long_2016_2022.2%>%filter(ola=="4") %>%select(constitucion=c29, # Confianza generalizadaeducacion=m01,# nivel educacionalcoalicion=c17, # coalicion politicaaut_demo=c25 # autoritarismo o democracia ) proc_data <- proc_data %>% sjlabelled::set_na(., na =c(-999, -888, -777, -666))# Comprobarnames(proc_data)
tabla <-prop.table(table(proc_data$educacion, proc_data$constitucion))dimnames(tabla) <-list(educacion=c("Básica", "Media", "Universitaria"),constitucion=c("Expertos", "Parlamento", "Asamblea") )tabla
constitucion
educacion Expertos Parlamento Asamblea
Básica 0.045514512 0.009894459 0.147097625
Media 0.091358839 0.010224274 0.317941953
Universitaria 0.094327177 0.005606860 0.278034301
Código
ACS <-CA(tabla, ncp=2, graph =FALSE)summary(ACS)
Call:
CA(X = tabla, ncp = 2, graph = FALSE)
The chi square of independence between the two variables is equal to 0.007128577 (p-value = 0.9999937 ).
Eigenvalues
Dim.1 Dim.2
Variance 0.006 0.001
% of var. 88.450 11.550
Cumulative % of var. 88.450 100.000
Rows
Iner*1000 Dim.1 ctr cos2 Dim.2 ctr cos2
Básica | 4.325 | 0.144 66.923 0.976 | 0.023 12.826 0.024 |
Media | 0.481 | -0.003 0.052 0.007 | -0.034 57.995 0.993 |
Universitaria | 2.322 | -0.074 33.024 0.897 | 0.025 29.179 0.103 |
Columns
Iner*1000 Dim.1 ctr cos2 Dim.2 ctr cos2
Expertos | 0.915 | -0.037 5.146 0.355 | 0.051 71.734 0.645 |
Parlamento | 5.986 | 0.481 94.558 0.996 | 0.030 2.869 0.004 |
Asamblea | 0.228 | -0.005 0.296 0.082 | -0.017 25.397 0.918 |
La salida del análisis de correspondencia simple nos entrega distintos atributos que es interesante mirar:
Eigenvalues: En un ACS tenemos un ‘autovalor’ por cada dimensión que nos entrega la varianza total de las variables que representa nuestro análisis y, además, un porcentaje de la varianza asociado a cada dimensión.
En cada fila y columna, nos entrega distintos valores, de los cuales nos interesan dos principales ‘ctr’ y ‘cos2’.
ctr: Es la contribución que cada categoría de la variable le da a cada dimensión (horizontal o vertical)
cos2: Es nuestra medida de calidad de nuestra medición. De la misma forma que la ‘contribución’, cada variable le entrega una mayor o menor calidad a nuestro análisis.
Ahora veamos estos mismos valores en un gráfico:
Código
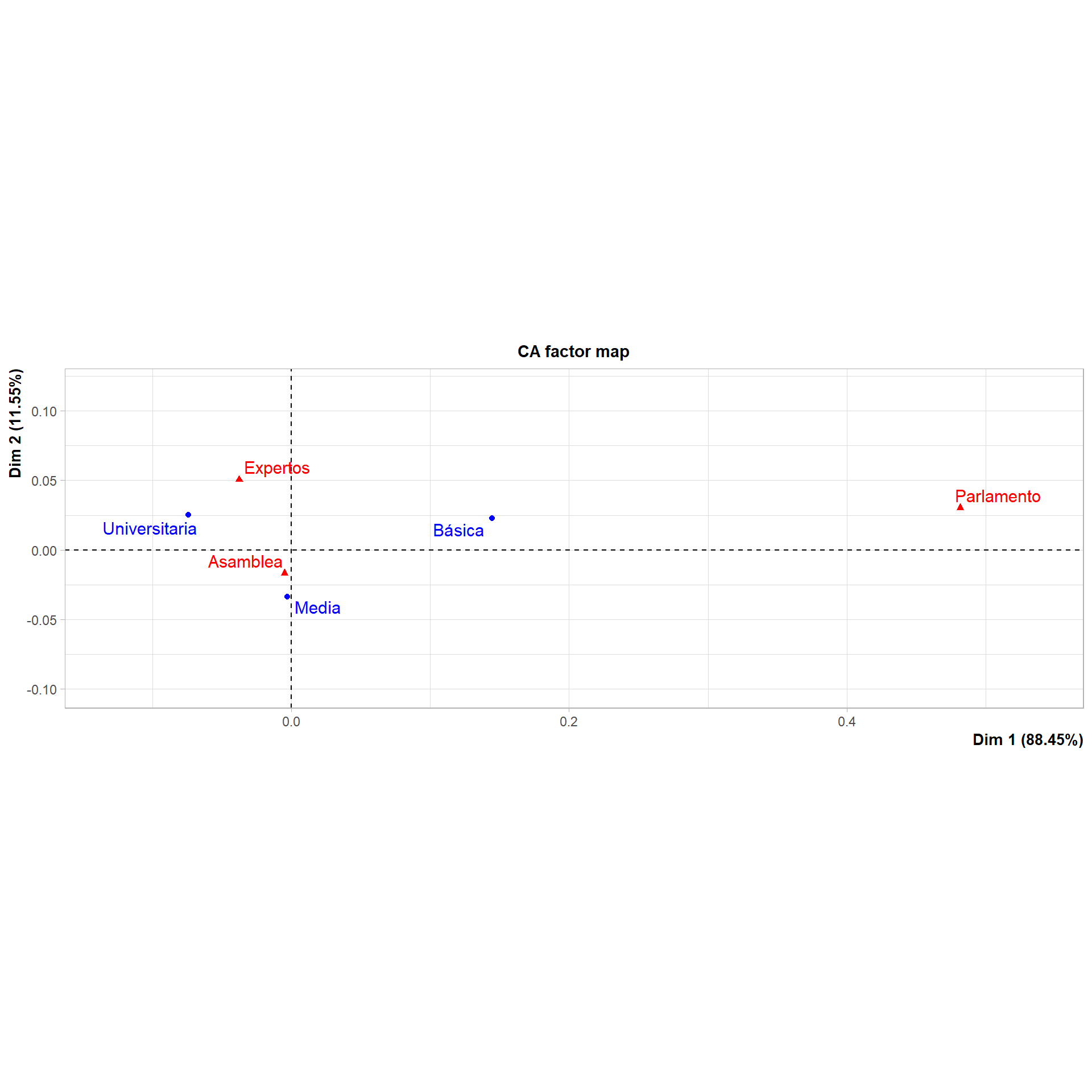
#Representación simultáneaplot.CA(ACS)
Tenemos las mismas dos dimensiones, una horizontal (Dim 1) que representa el 88.45% de la varianza de nuestras variables y una dimensión vertical (Dim 2) que representa el 11.5% de la varianza. Esto se representa gráficamente en que la mayoría de las variables están más distantes horizontalmente que verticalmente. Además, la mayor contribución a la varianza de la dimensión 1 está por las categorías Universitaria (33.024), Básica (66.923) y Parlamento (94.558)
Probemos otra correspondencia simple
Código
tabla <-prop.table(table(proc_data$educacion, proc_data$aut_demo))dimnames(tabla) <-list(educacion=c("Básica", "Media", "Universitaria"),aut_demo=c("Democracia", "Autoritarismo", "Da lo mismo","Ninguno") )tabla
aut_demo
educacion Democracia Autoritarismo Da lo mismo Ninguno
Básica 0.10680191 0.01998807 0.07875895 0.02058473
Media 0.23359189 0.03550119 0.11634845 0.03490453
Universitaria 0.25924821 0.03251790 0.03729117 0.02446301
Código
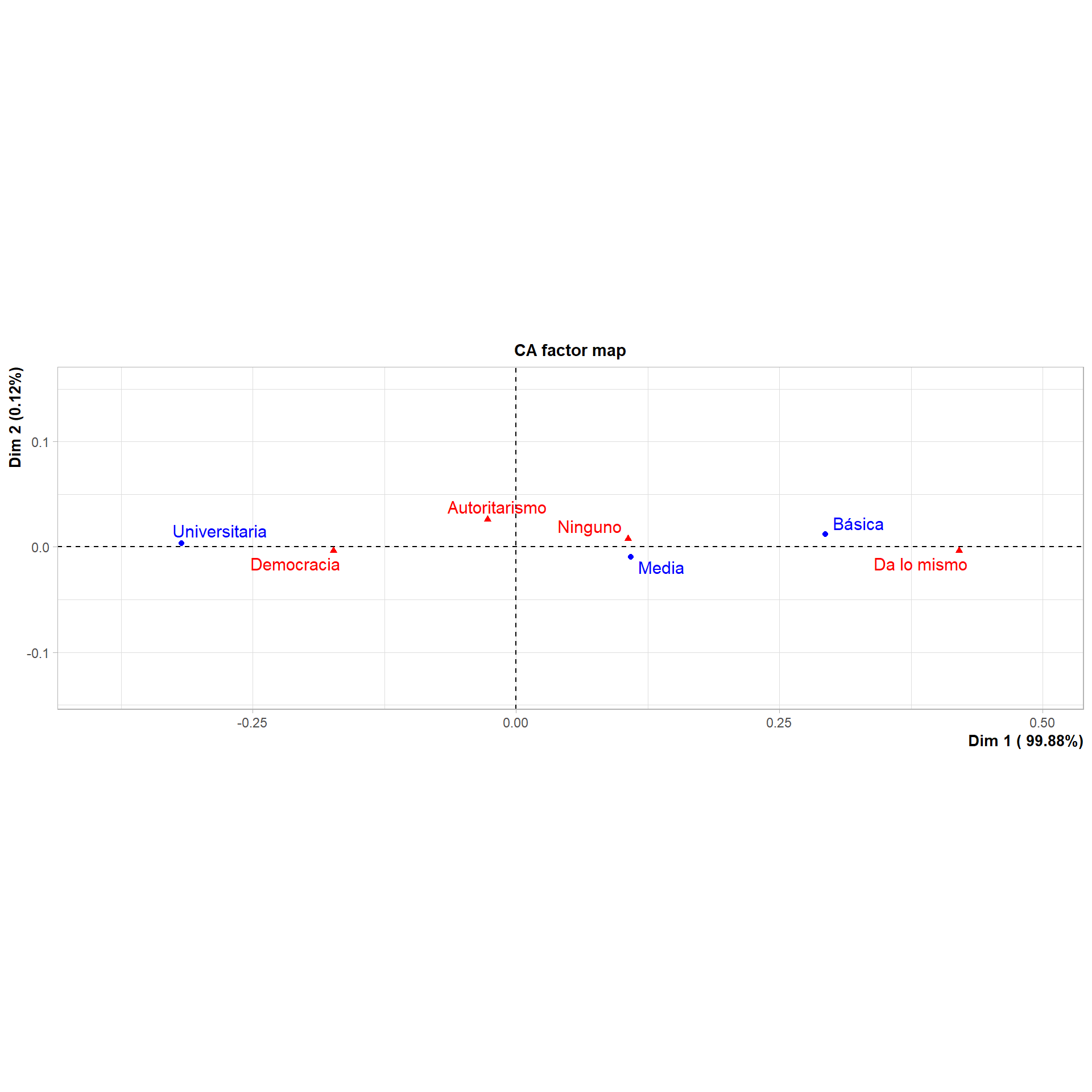
ACS <-CA(tabla, ncp=2, graph =FALSE)summary(ACS)
Call:
CA(X = tabla, ncp = 2, graph = FALSE)
The chi square of independence between the two variables is equal to 0.06017212 (p-value = 0.9999956 ).
Eigenvalues
Dim.1 Dim.2
Variance 0.060 0.000
% of var. 99.875 0.125
Cumulative % of var. 99.875 100.000
Rows
Iner*1000 Dim.1 ctr cos2 Dim.2 ctr cos2
Básica | 19.531 | 0.294 32.443 0.998 | 0.012 44.944 0.002 |
Media | 5.028 | 0.109 8.304 0.993 | -0.009 49.662 0.007 |
Universitaria | 35.614 | -0.317 59.254 1.000 | 0.003 5.394 0.000 |
Columns
Iner*1000 Dim.1 ctr cos2 Dim.2 ctr cos2
Democracia | 18.006 | -0.173 29.949 1.000 | -0.003 9.468 0.000 |
Autoritarismo | 0.124 | -0.027 0.107 0.518 | 0.026 79.512 0.482 |
Da lo mismo | 41.134 | 0.421 68.441 1.000 | -0.004 4.276 0.000 |
Ninguno | 0.908 | 0.106 1.503 0.994 | 0.008 6.744 0.006 |
Siguiendo la lógica del análisis que existe en el Análisis de Componentes Principales, que permite “reducir” las dimensiones de un data frame a partir de generar nuevos ejes o componentes que sirven a manera de “resumen” de las variables cuantitativas originales, en el análisis MCA también es posible construir dichos componentes o ejes a partir de variables categóricas.
Una vez que se generan los nuevos componentes, es importante identificar la capacidad explicativa del total de los casos que cada una proporciona. Para ello es importante revisar la proporción de varianzas que “retiene” cada una de estas dimensiones o ejes. Y puede ser extraído a partir de la función get_eigenvalue() de la siguiente manera:
En la tabla anterior se muestran del lado de las columnas los componentes o ejes nuevos, resultados del análisis MCA, mientras que en la primer columna se muestran los eigenvalores o el tamaño de las varianzas que explica cada uno, mientras que en la segunda columna se muestra el porcentaje de la varianza total que es explicado por cada eje o dimensión. En la tercer columna se muestra el porcentaje de varianza acumulado.
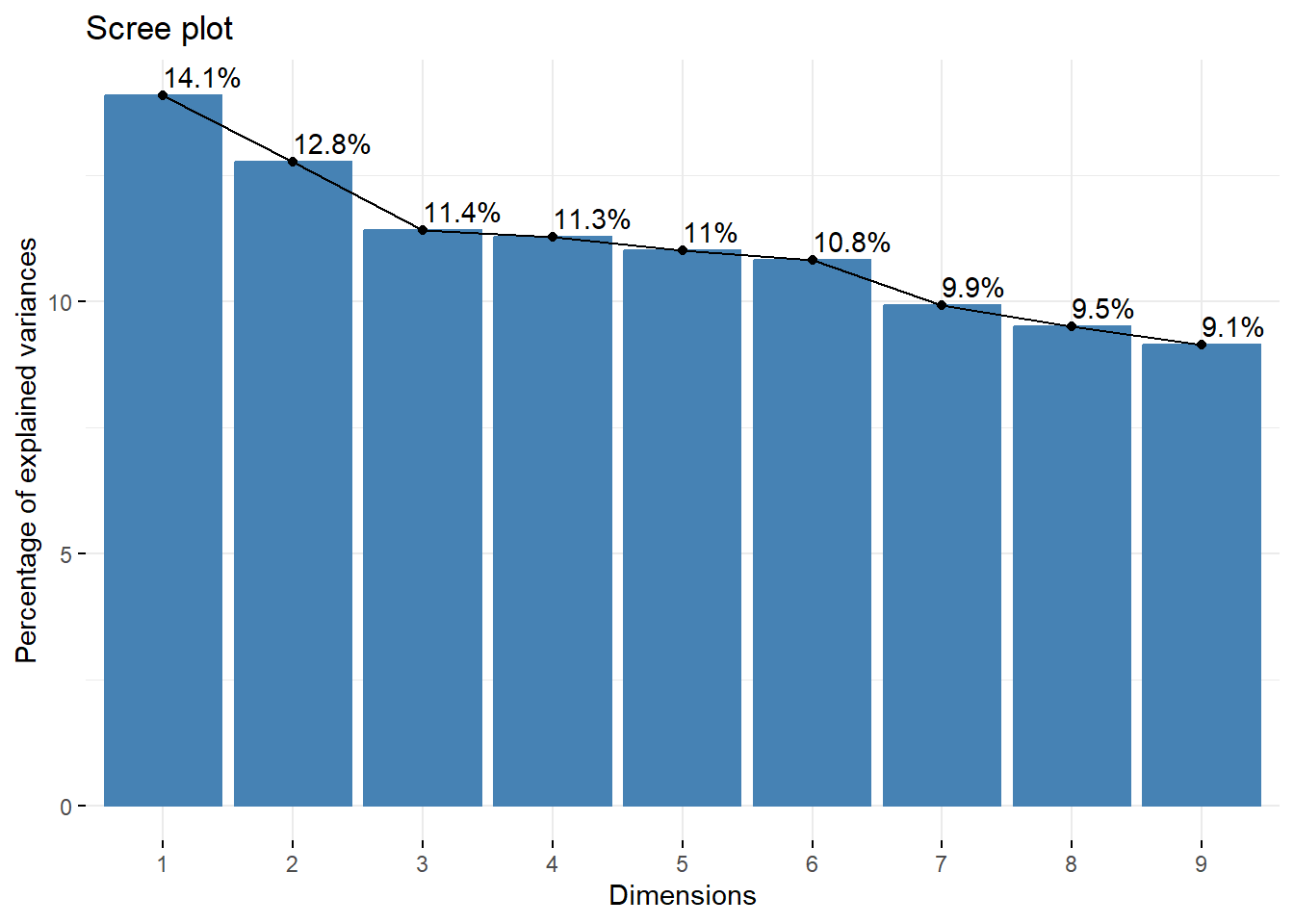
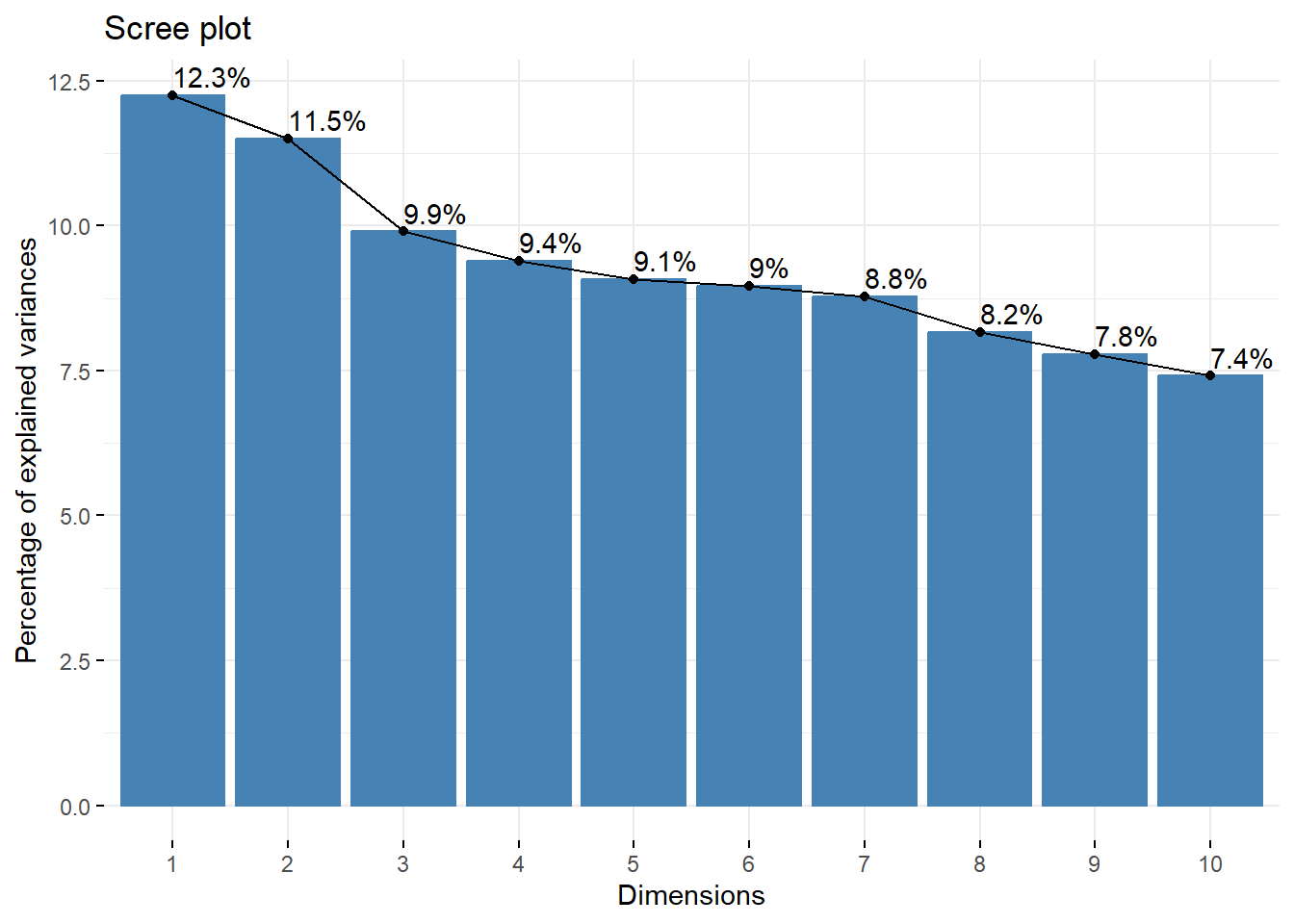
También es posible visualizar los porcentajes de varianza explicados por cada dimensión MCA, a partir de usar el comando fviz_screeplot(), con el que se puede crear un “scree plot.”
Código
fviz_screeplot(ACM, addlabels =TRUE)
Si una dimensión explica, por ejemplo, el 14.1% de la inercia o varianza, significa que la mayoría de la variabilidad en las relaciones entre categorías puede entenderse a través de esta dimensión.
Es importante interpretar el contenido de cada dimensión. A menudo, la primera dimensión puede representar la principal diferencia entre grupos de categorías (por ejemplo, ideología política en una encuesta de actitudes), mientras que la segunda dimensión podría representar una diferencia secundaria (como la educación o el nivel socioeconómico).
Representación gráfica
Código
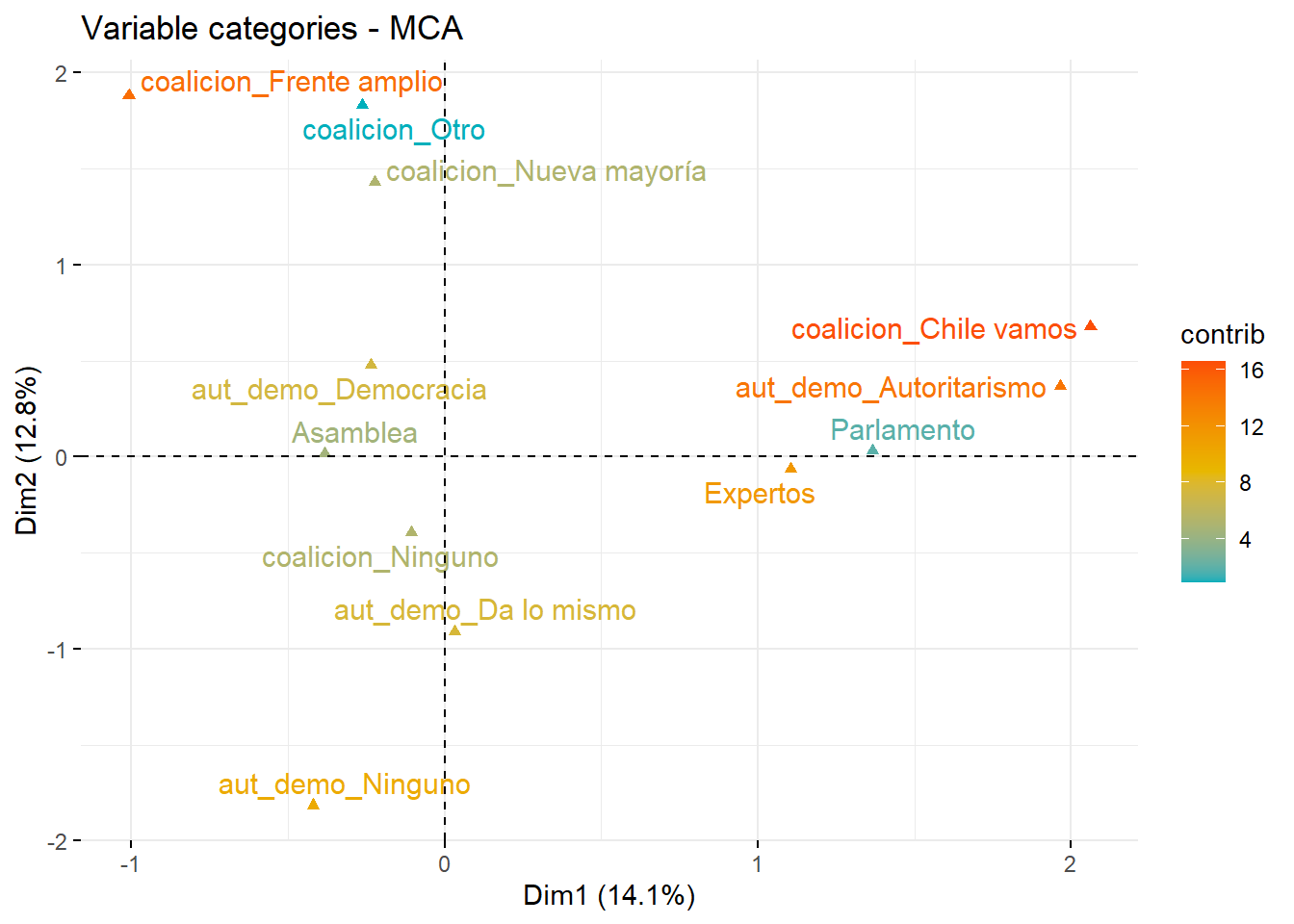
fviz_mca_var(ACM, #objeto tipo lista con resultados mcacol.var ="contrib", #definición de los colores a partir del valor cos2gradient.cols =c("#00AFBB", "#E7B800", "#FC4E07"), #definición de la paleta de coloresrepel =TRUE, # evitar solapamientos de etiquetas,max.overlaps ="ggrepel.max.overlaps", #aumentar el tamaño de solapamientosggtheme =theme_minimal() )
Podemos interpretar este gráfico de una forma similar al de un ACS, pero además podemos identificar de mejor manera la agrupación de ciertas categorías de variables. ¿Existe algún patrón que identificar?
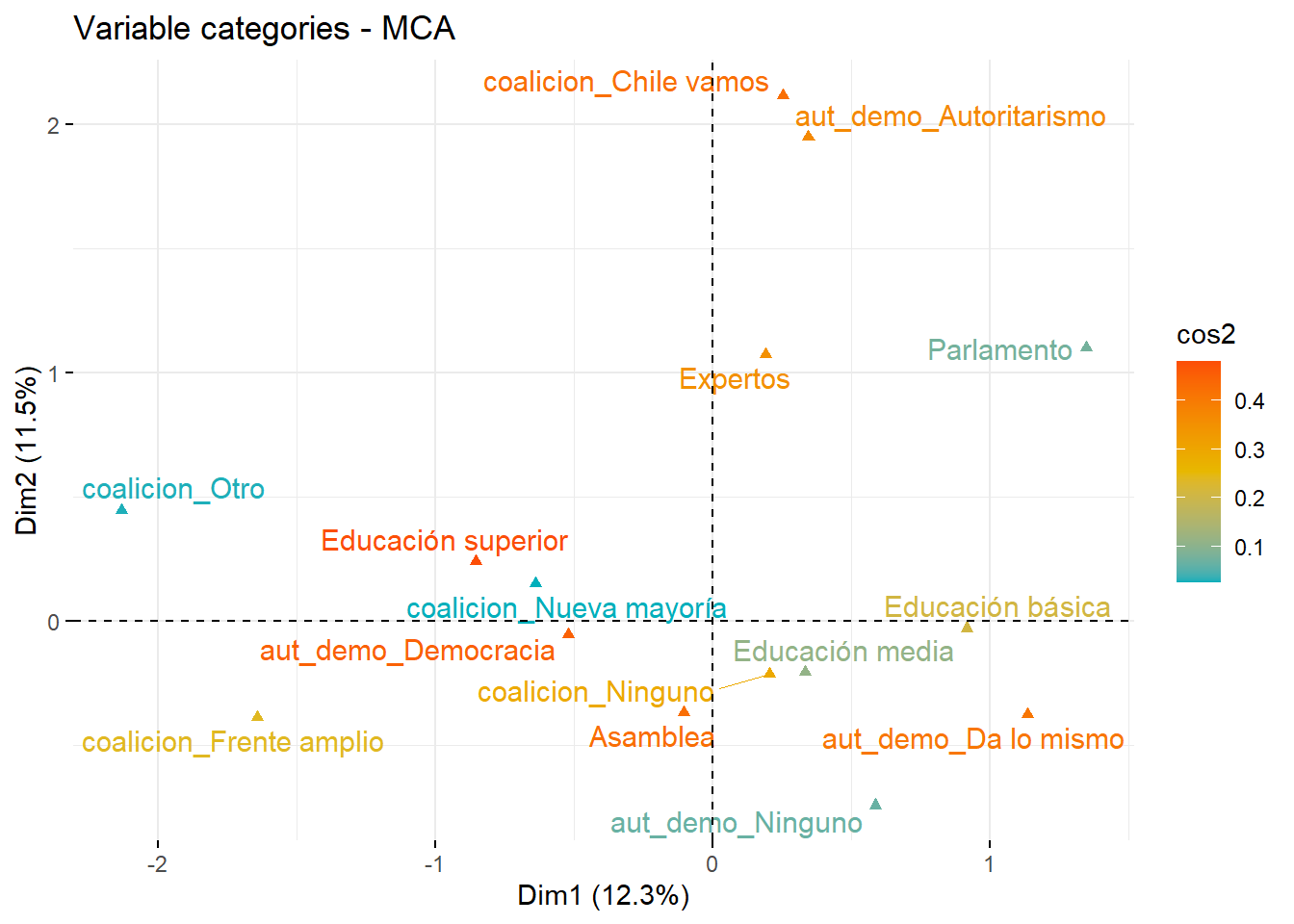
fviz_mca_var(ACM, #objeto tipo lista con resultados mcacol.var ="cos2", #definición de los colores a partir del valor cos2gradient.cols =c("#00AFBB", "#E7B800", "#FC4E07"), #definición de la paleta de coloresrepel =TRUE, # evitar solapamientos de etiquetas,max.overlaps ="ggrepel.max.overlaps", #aumentar el tamaño de solapamientosggtheme =theme_minimal() )
Ejecutar el código
---title: "Análisis de correspondencia múltiple"date: "2024-09-04"lang: esoutput: number_sections: true---```{r setup, include=FALSE}knitr::opts_chunk$set(echo =TRUE, message =FALSE,warning =FALSE)```# Objetivo de la prácticaLa siguiente práctica tiene el objetivo de introducir la idea central del análisis de correspondencia. Para ello, utilizaremos la base de datos de la cuarta ola del Estudio Longitudinal Social de Chile (2019) con el objetivo de analizar agrupaciones de variables categóricas nominales.# Preparación datosComencemos por preparar nuestros datos. Iniciamos cargando las librerías necesarias.```{r librerias, collapse=TRUE}pacman::p_load(tidyverse, # Manipulacion datos sjPlot, # Tablas psych, # Correlaciones DescTools, # Tablas ggplot2, # graficos en general broom, rempsyc, FactoMineR, # analisis de correspondencia factoextra # analisis de correspondencia )options(scipen =999) # para desactivar notacion cientificarm(list =ls()) # para limpiar el entorno de trabajo```Cargamos los datos directamente desde internet.```{r datos}#cargamos la base de datos desde internetload(url("https://dataverse.harvard.edu/api/access/datafile/7245118")) dim(elsoc_long_2016_2022.2)```Contamos con 750 variables (columnas) y 18035 observaciones (filas).```{r}proc_data <- elsoc_long_2016_2022.2%>%filter(ola=="4") %>%select(constitucion=c29, # Confianza generalizadaeducacion=m01,# nivel educacionalcoalicion=c17, # coalicion politicaaut_demo=c25 # autoritarismo o democracia ) proc_data <- proc_data %>% sjlabelled::set_na(., na =c(-999, -888, -777, -666))# Comprobarnames(proc_data)proc_data$educacion <- car::recode(proc_data$educacion, "c(1,2,3)=1; c(4,5)=2; c(6,7,8,9,10)=3")proc_data$educacion <- sjlabelled::set_labels(proc_data$educacion,labels=c( "Educación básica"=1,"Educación media"=2,"Educación superior"=3))proc_data$constitucion <- sjlabelled::set_labels(proc_data$constitucion,labels=c( "Expertos"=1,"Parlamento"=2,"Asamblea"=3))proc_data$coalicion <- sjlabelled::set_labels(proc_data$coalicion,labels=c( "Chile vamos"=1,"Nueva mayoría"=2,"Frente amplio"=3,"Otro"=4,"Ninguno"=5))proc_data$aut_demo <- sjlabelled::set_labels(proc_data$aut_demo,labels=c( "Democracia"=1,"Autoritarismo"=2,"Da lo mismo"=3,"Ninguno"=4))sjmisc::frq(proc_data$educacion)sjmisc::frq(proc_data$constitucion)sjmisc::frq(proc_data$coalicion)sjmisc::frq(proc_data$aut_demo)proc_data <- proc_data %>%mutate(across(everything(), sjlabelled::as_label))```# Tablas de contingencia```{r}sjPlot::sjt.xtab(var.row = proc_data$educacion, var.col = proc_data$constitucion, show.summary = F, emph.total = T, show.row.prc = T, # porcentaje filashow.col.prc = T, # porcentaje columnaencoding="UTF-8")```# Prueba de hipótesis con Chi-cuadradocálculo directo en R:```{r, collapse=TRUE}chi_results1 <-chisq.test(table(proc_data$educacion, proc_data$constitucion))stats.table <-tidy(chi_results1)nice_table(stats.table)``````{r}chi_results2 <-chisq.test(table(proc_data$educacion, proc_data$coalicion))stats.table <-tidy(chi_results1)nice_table(stats.table)``````{r}chi_results3 <-chisq.test(table(proc_data$constitucion, proc_data$coalicion))stats.table <-tidy(chi_results3)nice_table(stats.table)```# Análisis de correspondencias simple```{r}tabla <-prop.table(table(proc_data$educacion, proc_data$constitucion))dimnames(tabla) <-list(educacion=c("Básica", "Media", "Universitaria"),constitucion=c("Expertos", "Parlamento", "Asamblea") )tablaACS <-CA(tabla, ncp=2, graph =FALSE)summary(ACS)```La salida del análisis de correspondencia simple nos entrega distintos atributos que es interesante mirar:* Eigenvalues: En un ACS tenemos un 'autovalor' por cada dimensión que nos entrega la varianza total de las variables que representa nuestro análisis y, además, un porcentaje de la varianza asociado a cada dimensión.* En cada fila y columna, nos entrega distintos valores, de los cuales nos interesan dos principales 'ctr' y 'cos2'. - ctr: Es la contribución que cada categoría de la variable le da a cada dimensión (horizontal o vertical) - cos2: Es nuestra medida de calidad de nuestra medición. De la misma forma que la 'contribución', cada variable le entrega una mayor o menor calidad a nuestro análisis.Ahora veamos estos mismos valores en un gráfico:```{r fig.width=10, fig.height=10}#Representación simultáneaplot.CA(ACS)```Tenemos las mismas dos dimensiones, una horizontal (Dim 1) que representa el 88.45% de la varianza de nuestras variables y una dimensión vertical (Dim 2) que representa el 11.5% de la varianza. Esto se representa gráficamente en que la mayoría de las variables están más distantes horizontalmente que verticalmente. Además, la mayor contribución a la varianza de la dimensión 1 está por las categorías Universitaria (33.024), Básica (66.923) y Parlamento (94.558)## Probemos otra correspondencia simple```{r}tabla <-prop.table(table(proc_data$educacion, proc_data$aut_demo))dimnames(tabla) <-list(educacion=c("Básica", "Media", "Universitaria"),aut_demo=c("Democracia", "Autoritarismo", "Da lo mismo","Ninguno") )tablaACS <-CA(tabla, ncp=2, graph =FALSE)summary(ACS)``````{r fig.width=10, fig.height=10}#Representación simultáneaplot.CA(ACS)```## Y con más categorías de respuesta?```{r}tabla <-prop.table(table(proc_data$educacion, proc_data$coalicion))dimnames(tabla) <-list(educacion=c("Básica", "Media", "Universitaria"),coalicion=c("Chile vamos", "Nueva mayoría", "Frente Amplio", "Otro", "Ninguno") )tablaACS <-CA(tabla, ncp=2, graph =FALSE)summary(ACS)``````{r fig.width=10, fig.height=10}#Representación simultáneaplot.CA(ACS)```## Y si juntamos otras? ¿cuál sería nuestra variable dependiente?```{r}tabla <-prop.table(table(proc_data$coalicion, proc_data$aut_demo))dimnames(tabla) <-list(coalicion=c("Chile vamos", "Nueva mayoría", "Frente Amplio", "Otro", "Ninguno"),aut_demo=c("Democracia", "Autoritarismo", "Da lo mismo","Ninguno") )tablaACS <-CA(tabla, ncp=3, graph =FALSE)``````{r fig.width=10, fig.height=10}#Representación simultáneaplot.CA(ACS)```# Análisis de correspondencia múltiple```{r}ACM <- dplyr::select(proc_data, constitucion, coalicion, aut_demo) %>%na.omit() %>%MCA(, graph =FALSE)summary(ACM)```## Eigen values / VarianzaSiguiendo la lógica del análisis que existe en el Análisis de Componentes Principales, que permite “reducir” las dimensiones de un data frame a partir de generar nuevos ejes o componentes que sirven a manera de “resumen” de las variables cuantitativas originales, en el análisis MCA también es posible construir dichos componentes o ejes a partir de variables categóricas.Una vez que se generan los nuevos componentes, es importante identificar la capacidad explicativa del total de los casos que cada una proporciona. Para ello es importante revisar la proporción de varianzas que “retiene” cada una de estas dimensiones o ejes. Y puede ser extraído a partir de la función get_eigenvalue() de la siguiente manera:```{r}eig_val <- factoextra::get_eigenvalue(ACM)head(eig_val, 10)```En la tabla anterior se muestran del lado de las columnas los componentes o ejes nuevos, resultados del análisis MCA, mientras que en la primer columna se muestran los eigenvalores o el tamaño de las varianzas que explica cada uno, mientras que en la segunda columna se muestra el porcentaje de la varianza total que es explicado por cada eje o dimensión. En la tercer columna se muestra el porcentaje de varianza acumulado.También es posible visualizar los porcentajes de varianza explicados por cada dimensión MCA, a partir de usar el comando fviz_screeplot(), con el que se puede crear un “scree plot.”```{r}fviz_screeplot(ACM, addlabels =TRUE)```Si una dimensión explica, por ejemplo, el 14.1% de la inercia o varianza, significa que la mayoría de la variabilidad en las relaciones entre categorías puede entenderse a través de esta dimensión.Es importante interpretar el contenido de cada dimensión. A menudo, la primera dimensión puede representar la principal diferencia entre grupos de categorías (por ejemplo, ideología política en una encuesta de actitudes), mientras que la segunda dimensión podría representar una diferencia secundaria (como la educación o el nivel socioeconómico).## Representación gráfica```{r}fviz_mca_var(ACM, #objeto tipo lista con resultados mcacol.var ="contrib", #definición de los colores a partir del valor cos2gradient.cols =c("#00AFBB", "#E7B800", "#FC4E07"), #definición de la paleta de coloresrepel =TRUE, # evitar solapamientos de etiquetas,max.overlaps ="ggrepel.max.overlaps", #aumentar el tamaño de solapamientosggtheme =theme_minimal() )```Podemos interpretar este gráfico de una forma similar al de un ACS, pero además podemos identificar de mejor manera la agrupación de ciertas categorías de variables. ¿Existe algún patrón que identificar?## Con todas las variables ```{r}ACM <- proc_data %>%na.omit() %>%MCA(, graph =FALSE)``````{r}fviz_screeplot(ACM, addlabels =TRUE)``````{r}fviz_mca_var(ACM, #objeto tipo lista con resultados mcacol.var ="cos2", #definición de los colores a partir del valor cos2gradient.cols =c("#00AFBB", "#E7B800", "#FC4E07"), #definición de la paleta de coloresrepel =TRUE, # evitar solapamientos de etiquetas,max.overlaps ="ggrepel.max.overlaps", #aumentar el tamaño de solapamientosggtheme =theme_minimal() )```